






Understanding Retransmission Timeouts (RTOs) and Application Performance
Back to top

March 7, 2011
Understanding Retransmission Timeouts (RTOs) and Application Performance
Let's talk about retransmission timeouts (RTOs). What are they and what can you do about them?
The Significance of TCP Retransmission Timeouts
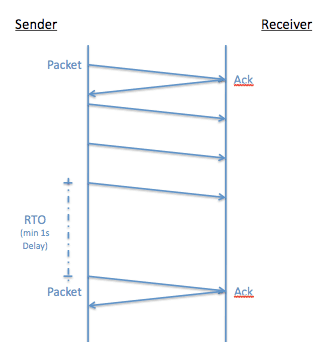
Reveal(x) captures a lot of application performance metrics. One of the most important of these performance metrics quantifies TCP retransmission timeouts (RTOs), which create havoc for network and application performance. TCP starts a retransmission timer when an outbound segment is handed down to IP. If there is no acknowledgment for the data in a given segment before the timer expires, then the segment is retransmitted. TCP retransmissions occur on the network all the time. Typically, they don't pose much of a problem; as the retransmission timer counts down, the packets are resent, and the network continues to hum along.
Understanding Retransmission Timeouts in TCP
How Reveal(x) Detects and Addresses RTOs
Reveal(x) spots RTOs by simulating the TCP state machines at the endpoints of the connection and inferring when problems occur, detecting issues such as bad congestion avoidance, Nagle delays, and PAWS drops.
Real-World Example of RTO Mitigation
In a real-world example, we received a call from one of our customers about a very high number of RTOs on some key servers. He asked us to help him validate and analyze the data, including identifying the specific TCP retransmission causes. We looked at the data together, and sure enough, during traffic spikes, the RTO metric would climb to approximately eight million. Because the Reveal(x) UI allows for easy drill-down, we were able to quickly determine that the majority of the RTOs could be traced to a single blade enclosure and two specific server instances.
Using this information, we pinpointed the problem quickly, allowing for a nearly immediate mean time to resolution (MTTR). The RTO metric helps to identify packet loss and to locate the congested links, shedding light on the TCP retransmission causes. There are a few areas within the network that could be likely causes: duplex mismatch on the switch, a bad cable, bad checksums, or driver issue. In this customer's case, we found an incorrect flow control setting, which was one of the key TCP retransmission causes. After adjusting this setting, the RTOs dropped by more than 90%, which was a big win for our customer and for the applications running on its servers.
Eliminating RTOs for Better Network Performance
In summary, retransmission timeouts result in serious network stalls and performance degradation, whether that's in the cloud or the data center. Reveal(x) makes it easy to identify RTOs and eliminate them quickly.
Want to see exactly how easy it is to monitor TCP round-trip times and retransmission timeouts in Reveal(x)? Explore our free online demo.
Discover more

